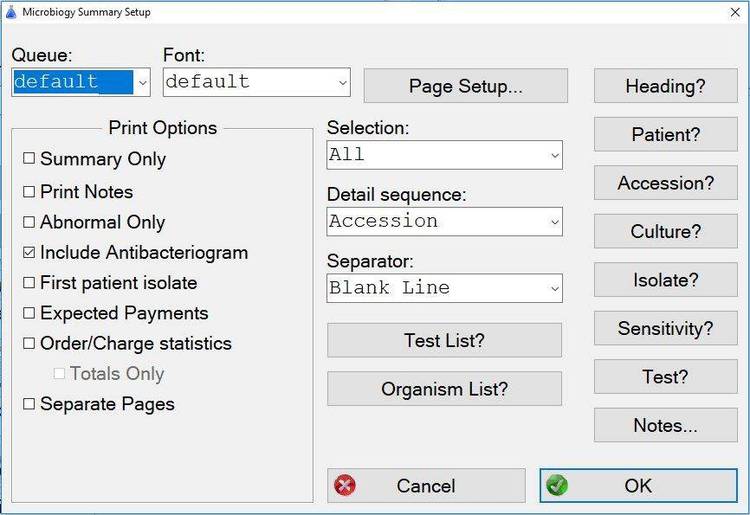
Supported Join Feature Description Inner Join Combines records from two tables whenever there are matching values. Left Join or Left Outer Join Returns all of the rows from the left of two tables, even if there are no matching values for records in the right table. Right Join or Right Outer Join Returns all of the rows from the right of two tables, even if there are no matching values for records in the left table. Full Join or Outer Join Returns all rows in both the left and right tables. Any time a row has no match in the other table, SELECT list columns from the other table contain null values. When there is a match between the tables, the entire result set row contains data values from the base tables.

Each row from the left table is combined with all rows from the right table. Old Join syntax Simply selects columns from multiple tables using the WHERE clause without using the JOIN keyword. Table joins are a powerful tool when organizing and analyzing data. However, refer to the documentation for your third-party reporting software for more complete information on building more complex queries.

Expression_n Expressions that are not encapsulated within an aggregate function and must be included in the GROUP BY Clause at the end of the SQL statement. Aggregate_function This is an aggregate function such as the SUM, COUNT, MIN, MAX, or AVG functions. Aggregate_expression This is the column or expression that the aggregate_function will be used on. There must be at least one table listed in the FROM clause. These are conditions that must be met for the records to be selected.

The expression used to sort the records in the result set. If more than one expression is provided, the values should be comma separated. ASC sorts the result set in ascending order by expression.

DESC sorts the result set in descending order by expression. The offset PRECEDING and offset FOLLOWING options vary in meaning depending on the frame mode. In ROWS mode, the offsetis an integer indicating that the frame starts or ends that many rows before or after the current row. In RANGE mode, use of an offset option requires that there be exactly one ORDER BY column in the window definition. Then the frame contains those rows whose ordering column value is no more than offset less than or more than the current row's ordering column value. In these cases the data type of the offset expression depends on the data type of the ordering column.

For numeric ordering columns it is typically of the same type as the ordering column, but for datetime ordering columns it is an interval. In all these cases, the value of the offsetmust be non-null and non-negative. Also, while the offset does not have to be a simple constant, it cannot contain variables, aggregate functions, or window functions.

The UNION operator computes the set union of the rows returned by the involved SELECTstatements. A row is in the set union of two result sets if it appears in at least one of the result sets. The two SELECT statements that represent the direct operands of the UNION must produce the same number of columns, and corresponding columns must be of compatible data types.

The UNION operator computes the set union of the rows returned by the involved SELECT statements. The two SELECTstatements that represent the direct operands of the UNION must produce the same number of columns, and corresponding columns must be of compatible data types. The presence of HAVING turns a query into a grouped query even if there is no GROUP BY clause. This is the same as what happens when the query contains aggregate functions but no GROUP BY clause. All the selected rows are considered to form a single group, and the SELECT list and HAVING clause can only reference table columns from within aggregate functions. Such a query will emit a single row if the HAVING condition is true, zero rows if it is not true.

Table functions are functions that produce a set of rows, made up of either base data types or composite data types . They are used like a table, view, or subquery in the FROM clause of a query. Columns returned by table functions can be included in SELECT, JOIN, or WHERE clauses in the same manner as columns of a table, view, or subquery. SQL Aggregate Functions SQL aggregate functions perform a calculation on a set of values in a column and return a single value. For instance, when comparing multiple tags, you could retrieve the minimum of the returned minimum values.

You usually use aggregate functions with the GROUP BY clause, but it is not required. Using the operators UNION, INTERSECT, and EXCEPT, the output of more than one SELECT statement can be combined to form a single result set. The UNION operator returns all rows that are in one or both of the result sets. The INTERSECToperator returns all rows that are strictly in both result sets. The EXCEPT operator returns the rows that are in the first result set but not in the second.
In all three cases, duplicate rows are eliminated unless ALL is specified. Spark also supports advanced aggregations to do multiple aggregations for the same input record set via GROUPING SETS, CUBE, ROLLUP clauses. The grouping expressions and advanced aggregations can be mixed in the GROUP BY clause and nested in a GROUPING SETS clause. See more details in the Mixed/Nested Grouping Analytics section.

When a FILTER clause is attached to an aggregate function, only the matching rows are passed to that function. Each sublist of GROUPING SETS may specify zero or more columns or expressions and is interpreted the same way as though it were directly in the GROUP BY clause. An empty grouping set means that all rows are aggregated down to a single group , as described above for the case of aggregate functions with no GROUP BY clause. ROLLUP is an extension of the GROUP BY clause that creates a group for each of the column expressions. Additionally, it "rolls up" those results in subtotals followed by a grand total. Under the hood, the ROLLUP function moves from right to left decreasing the number of column expressions that it creates groups and aggregations on.

Since the column order affects the ROLLUP output, it can also affect the number of rows returned in the result set. It is not permissible to include column names in a SELECT clause that are not referenced in the GROUP BY clause. The only column names that can be displayed, along with aggregate functions, must be listed in the GROUP BY clause. Since ENAME is not included in the GROUP BYclause, an error message results. The above query includes the GROUP BY DeptId clause, so you can include only DeptId in the SELECT clause. You need to use aggregate functions to include other columns in the SELECT clause, so COUNT is included because we want to count the number of employees in the same DeptId.

In this example, the columns product_id, p.name, and p.price must be in the GROUP BY clause since they are referenced in the query select list . The column s.units does not have to be in the GROUP BY list since it is only used in an aggregate expression (sum(...)), which represents the sales of a product. For each product, the query returns a summary row about all sales of the product.

GROUP BY will condense into a single row all selected rows that share the same values for the grouped expressions. An expressioncan be an input column name, or the name or ordinal number of an output column , or an arbitrary expression formed from input-column values. In case of ambiguity, a GROUP BY name will be interpreted as an input-column name rather than an output column name. The GROUP BY clause is often used with aggregate functions such as AVG(), COUNT(), MAX(), MIN() and SUM().

In this case, the aggregate function returns the summary information per group. For example, given groups of products in several categories, the AVG() function returns the average price of products in each category. You must use the aggregate functions such as COUNT(), MAX(), MIN(), SUM(), AVG(), etc., in the SELECT query. The result of the GROUP BY clause returns a single row for each value of the GROUP BY column.

Expression can be an input column name, or the name or ordinal number of an output column , or an arbitrary expression formed from input-column values. This syntax allows users to perform analysis that requires aggregation on multiple sets of columns in a single query. Complex grouping operations do not support grouping on expressions composed of input columns. In this case, the server is free to choose any value from each group, so unless they are the same, the values chosen are nondeterministic, which is probably not what you want. Furthermore, the selection of values from each group cannot be influenced by adding an ORDER BY clause.

Result set sorting occurs after values have been chosen, and ORDER BY does not affect which value within each group the server chooses. The INTERSECT operator computes the set intersection of the rows returned by the involved SELECT statements. A row is in the intersection of two result sets if it appears in both result sets. Aggregate functions, if any are used, are computed across all rows making up each group, producing a separate value for each group . The SELECT statement used in the GROUP BY clause can only be used contain column names, aggregate functions, constants and expressions. The GROUP BY clause is a SQL command that is used to group rows that have the same values.
Optionally it is used in conjunction with aggregate functions to produce summary reports from the database. A table reference can be a table name (possibly schema-qualified), or a derived table such as a subquery, a JOIN construct, or complex combinations of these. If more than one table reference is listed in the FROM clause, the tables are cross-joined (that is, the Cartesian product of their rows is formed; see below).

The aggregate functions do not include rows that have null values in the columns involved in the calculations; that is, nulls are not handled as if they were zero. You can use SELECT statements to retrieve information from any of the columns in any of the Historian tables. The SELECT statement returns a snapshot of data at the given time of the query. In the SQL-92 standard, an ORDER BY clause can only use output column names or numbers, while a GROUP BY clause can only use expressions based on input column names.

The GROUP BY clause is used in a SELECT statement to group rows into a set of summary rows by values of columns or expressions. FILTER is a modifier used on an aggregate function to limit the values used in an aggregation. All the columns in the select statement that aren't aggregated should be specified in a GROUP BY clause in the query. MySQL extends the standard SQL use of GROUP BY so that the select list can refer to nonaggregated columns not named in the GROUP BY clause.

You can use this feature to get better performance by avoiding unnecessary column sorting and grouping. However, this is useful primarily when all values in each nonaggregated column not named in the GROUP BY are the same for each group. The server is free to choose any value from each group, so unless they are the same, the values chosen are nondeterministic.

Result set sorting occurs after values have been chosen, and ORDER BY does not affect which values within each group the server chooses. A number of constructs can be classified as an expression but do not follow any general syntax rules. These generally have the semantics of a function or operator. For information about SQL value expressions and function calls, see "Querying Data" in the Greenplum Database Administrator Guide. It filters non-aggregated rows before the rows are grouped together. To filter grouped rows based on aggregate values, use the HAVING clause.

The HAVING clause takes any expression and evaluates it as a boolean, just like the WHERE clause. As with the select expression, if you reference non-grouped columns in the HAVINGclause, the behavior is undefined. This statement will return an error because you cannot use aggregate functions in a WHERE clause. WHERE is used with GROUP BY when you want to filter rows before grouping them. If the WITH ORDINALITY clause is specified, an additional column of type bigint will be added to the function result columns. This column numbers the rows of the function result set, starting from 1.

SQL allows the user to store more than 30 types of data in as many columns as required, so sometimes, it becomes difficult to find similar data in these columns. Group By in SQL helps us club together identical rows present in the columns of a table. This is an essential statement in SQL as it provides us with a neat dataset by letting us summarize important data like sales, cost, and salary.

Using SQL statements, you can retrieve information from the columns and rows in a specified table or tables. You are only limited by the amount of memory on your system when determining the number of data rows that you can retrieve from a table. The result of EXCEPT does not contain any duplicate rows unless the ALL option is specified.

With ALL, a row that has m duplicates in the left table and n duplicates in the right table will appear max(m-n,0) times in the result set. DISTINCT can be written to explicitly specify the default behavior of eliminating duplicate rows. This left-hand row is extended to the full width of the joined table by inserting null values for the right-hand columns. Note that only the JOINclause's own condition is considered while deciding which rows have matches.

In the SQL-92 standard, an ORDER BY clause may only use result column names or numbers, while a GROUP BY clause may only use expressions based on input column names. Greenplum Database extends each of these clauses to allow the other choice as well (but it uses the standard's interpretation if there is ambiguity). Greenplum Database also allows both clauses to specify arbitrary expressions. Note that names appearing in an expression are always taken as input-column names, not as result-column names. However, you can use the GROUP BY clause with CUBE, GROUPING SETS, and ROLLUP to return summary values for each group.
Instead of performing aggregate functions on an the entire set of retrieved rows, you can split the rows into groups and then perform the aggregate function on each of them. When you use a GROUP BY clause, you will get a single result row for each group of rows that have the same value for the expression given in GROUP BY. A GROUP BY clause can include multiple group_expressions and multiple CUBE|ROLLUP|GROUPING SETSs. GROUPING SETS can also have nested CUBE|ROLLUP|GROUPING SETS clauses, e.g. GROUPING SETS(ROLLUP, CUBE), GROUPING SETS(warehouse, GROUPING SETS(location, GROUPING SETS(ROLLUP, CUBE))). CUBE|ROLLUP is just a syntax sugar for GROUPING SETS, please refer to the sections above for how to translate CUBE|ROLLUP to GROUPING SETS.
Group_expression can be treated as a single-group GROUPING SETS under this context. For multiple GROUPING SETS in the GROUP BY clause, we generate a single GROUPING SETS by doing a cross-product of the original GROUPING SETSs. For nested GROUPING SETS in the GROUPING SETS clause, we simply take its grouping sets and strip it. For example, GROUP BY warehouse, GROUPING SETS(, ()), GROUPING SETS(, , , ())and GROUP BY warehouse, ROLLUP, CUBE is equivalent to GROUP BY GROUPING SETS( , , , , , , , ).
